Création d'une infrastructure Cloud de monitoring
Découvrez un système complet de surveillance en temps réel d'un serveur informatique dans le cloud afin d’anticiper les problèmes avant qu’ils ne surviennent.
Comprendre l’objectif du projet
Pourquoi ce système de monitoring cloud a été créé
À quoi sert ce projet ?
Dans un environnement cloud, un serveur doit être surveillé en permanence. Sans monitoring, on ne sait pas s’il ralentit, s’il manque de mémoire ou s’il tombe en panne.
Ce projet permet donc de créer un système qui observe automatiquement le serveur et affiche toutes ses informations importantes sur un tableau de bord visuel.
Les outils utilisés
Chaque technologie joue un rôle précis dans le système
Comment le système est construit
Le projet repose sur plusieurs outils qui travaillent ensemble :
- AWS EC2 héberge le serveur dans le cloud
- Docker permet de lancer les services facilement
- Prometheus collecte les données du serveur
- Grafana affiche les graphiques de monitoring
Le fonctionnement en images
Voici les différentes étapes de mise en place de l’infrastructure Cloud, depuis la création du serveur jusqu’à la visualisation des métriques.
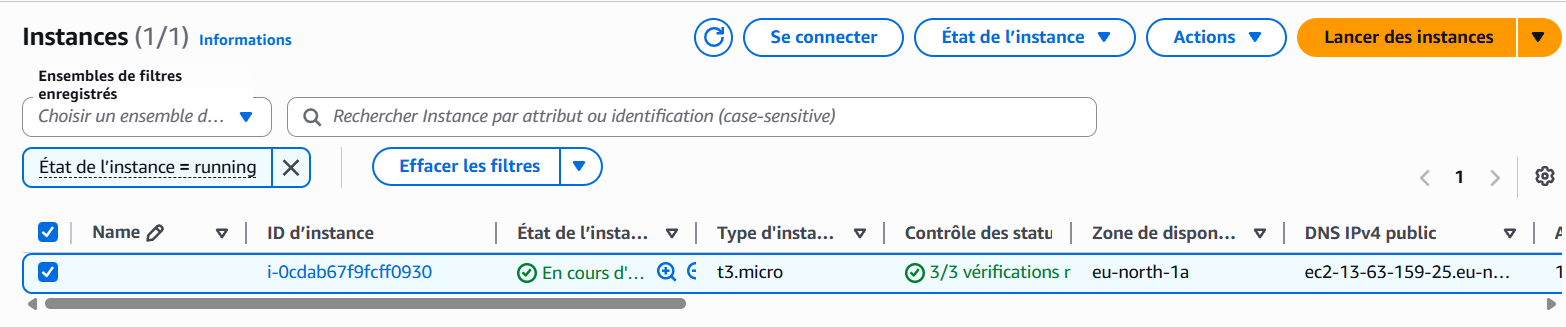
1. Création de l’instance AWS EC2
La première étape consiste à créer un serveur virtuel sur AWS (EC2). C’est sur cette machine que tout le système de monitoring sera installé.
On choisit un système Linux, on configure les accès réseau, puis on démarre l’instance pour obtenir un serveur accessible à distance.

2. Déploiement des services avec Docker
Une fois le serveur prêt, les outils de monitoring sont installés via Docker. Cela permet de lancer facilement plusieurs services isolés.
Chaque composant (Grafana, Prometheus, Node Exporter) fonctionne dans un conteneur.
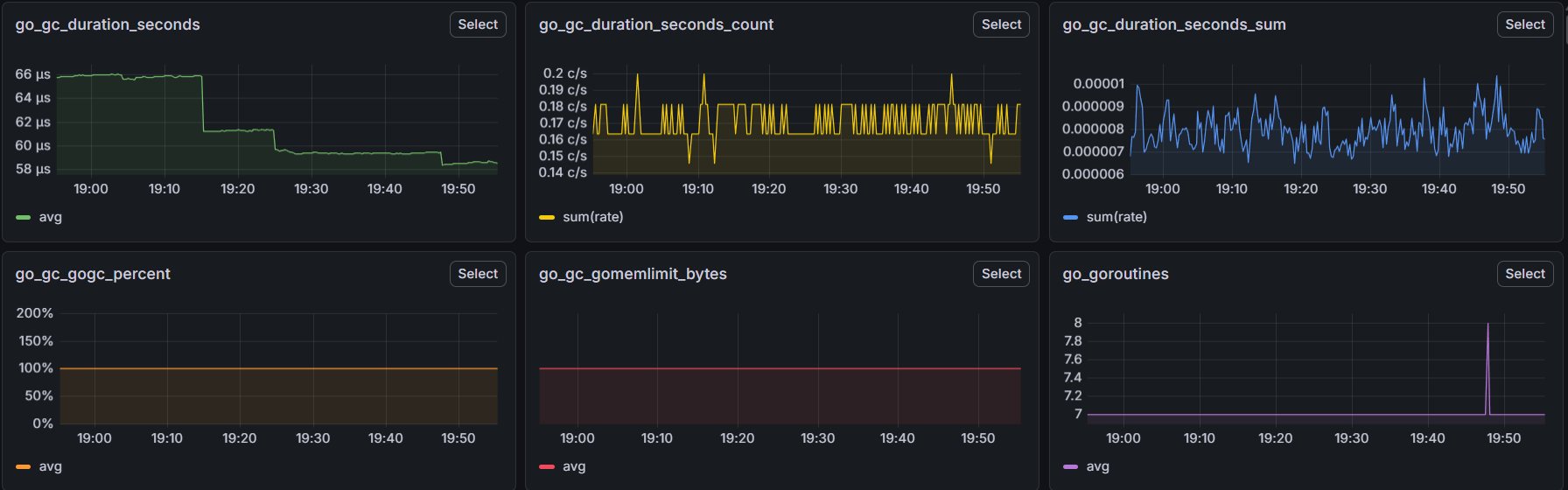
3. Collecte des métriques avec Prometheus
Prometheus récupère en continu les données du serveur : utilisation CPU, mémoire, disque et réseau.
Ces données sont stockées pour être analysées et affichées ensuite.
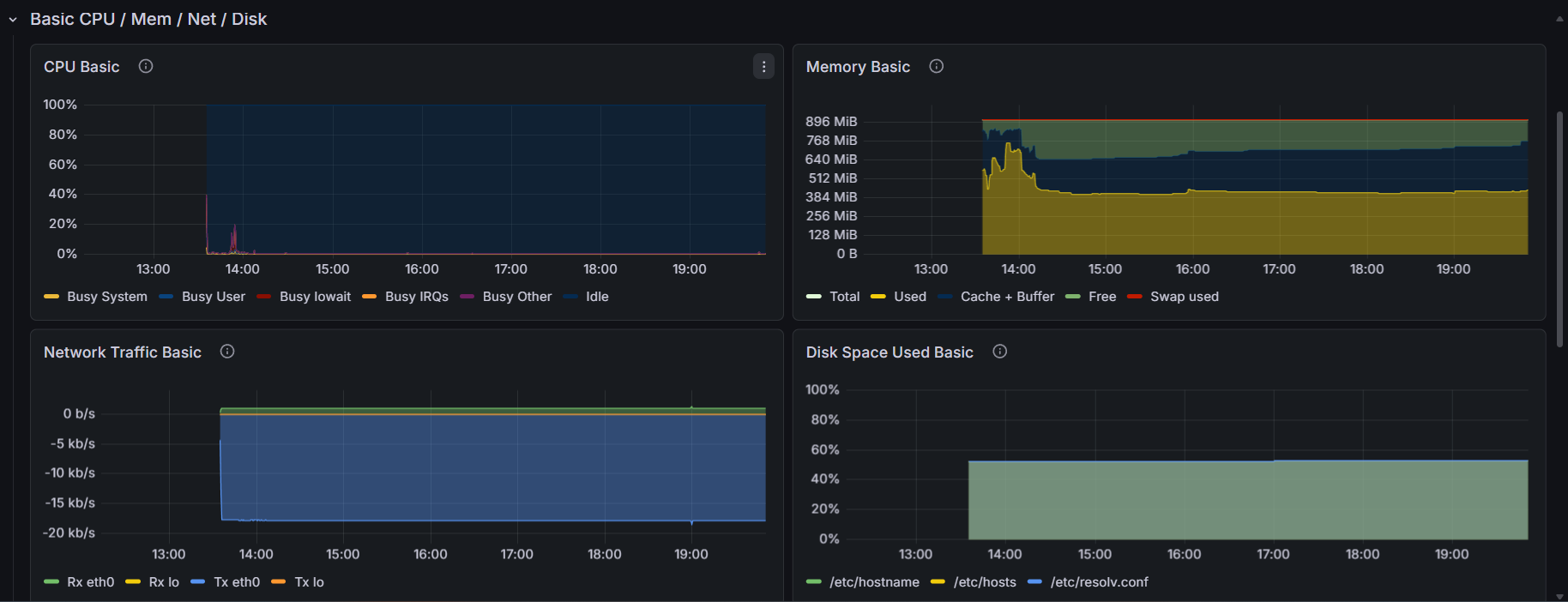
4. Visualisation des performances
Grafana transforme les données en graphiques lisibles. On peut voir en temps réel l’état du serveur.
Cela permet de détecter immédiatement les pics de charge ou anomalies.
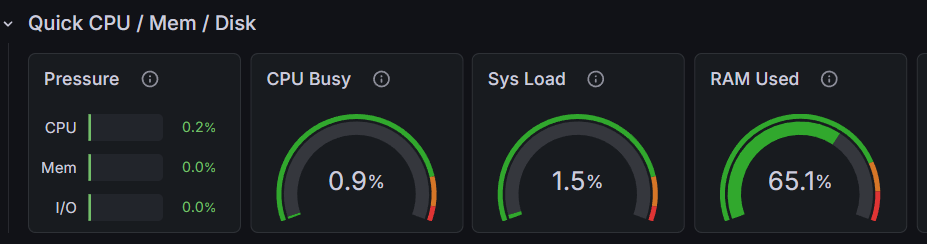
5. Supervision complète du système
Le dashboard final regroupe toutes les métriques du serveur en un seul endroit. Cela donne une vision globale de l’infrastructure.
L’objectif est d’avoir une surveillance continue et centralisée du système Cloud.
Ce que ce projet permet de réaliser
Résultat final
À la fin du projet, nous obtenons une plateforme complète capable de surveiller un serveur cloud en continu.
Cela permet :
- d’éviter les pannes
- de surveiller les performances
- d’améliorer la stabilité d’un système cloud